缘起:
最近想重看一遍漫画《海贼王》,腾讯动漫上有完整的免费资源,先是在腾讯上看了一阵,后来又找了一个海贼小站的专门论坛,在其上的阅读体验更简洁一些。但是,无论网页怎样简化,浏览器的框架和网站的广告总是躲不掉,占据着阅读的视野。
于是,就想着把漫画所有的图片抓取到本地磁盘,然后通过图片查看器开全屏,悠哉悠哉地看……漫……画……
有了需求,说干就干。
Python 实现爬虫,第 1 版
这段时间又重新把 Python 用起来了,想的是如果什么问题都用 Java 解决,方式太重了,而且手里常备一个熟练的动态语言也是极其必要的,所以,稍微简单的任务,比如,文本处理、批量修改文件等,都改用 Python 了。另外,我在 github 上维护了一个pythong 小工具工程,专门存放日常用到的 Python 脚本,留档下来方便以后遇到类似问题可以拿来直接用。
所以,这次的漫画图片抓取,我计划用 Python 编码实现。
此前已经编写过类似的网页文字和多媒体爬取脚本,见上面提到 github 工程中的download_mp3_and_dialog.py文件,它使用的是 Lxml 库。著名的网页抓取方式还有 Beautiful Soup 和正则等,当然,也可以用更强大了爬虫框架,只是,我的需求太简单,杀鸡焉用牛刀。
Python 编码部分不复杂,编程主要的工作其实在分析网页结构,找到图片下载链接这些工作上。
网页分析,CSS 元素定位
为了下载漫画,我们分析网页需要搞清楚 3 部分有用的内容。
1.动漫每话的网页地址
经过分析,我发现这个网站在组织每话的 url 时,规则非常简单且规整。比如,第 1 话是www.fuckgfw.com/onepiece/0001,那么,第 188 话就是www.fuckgfw.com/onepiece/0188,以此类推。
再找到《海贼王》当前的最后一话是 917 话,剩下的就是 for 循环和字符串拼接了。
重要说明!!!
本文仅是技术分享,为了避免有人阅读本文后拿人家的网站做测试,本文隐去抓取的网站域名。这事儿咱一个人干也就干了,可不好传播~~
2.每话的题目
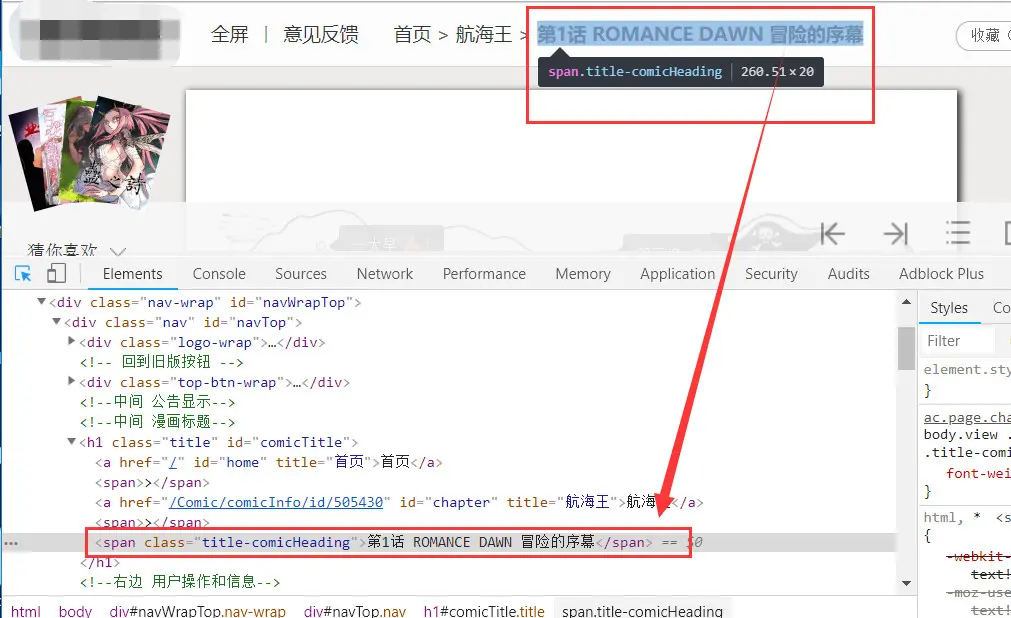
页面顶部就有漫画每话的题目,在页面源码中搜索后可以确认 span标签的class属性值title-comicHeading 在页面中是唯一的,我们就用它来定位元素,然后获取元素上的文本。
标题的 CSS Selector 语法是 span.title-comicHeading 。
![imag]()
3.每话中图片资源地址
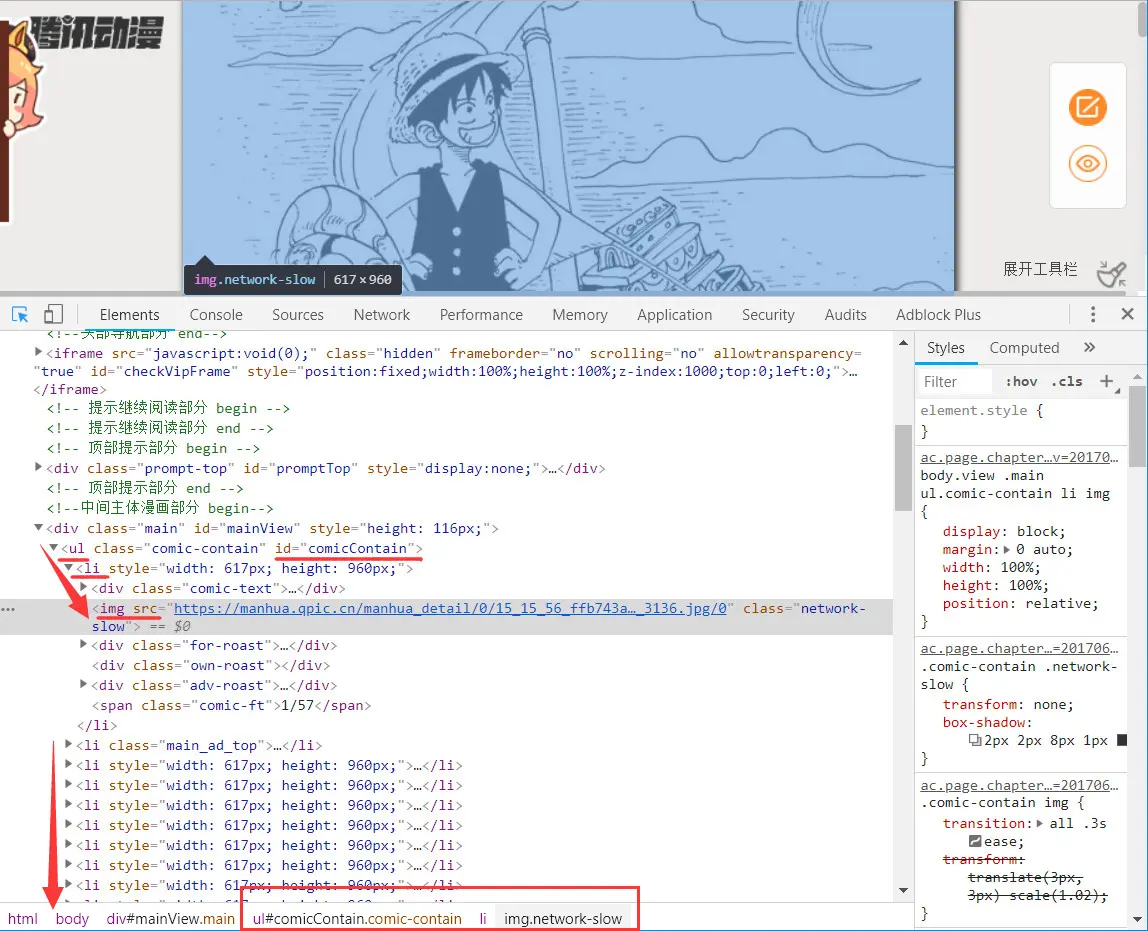
每话都有数量不等的漫画图片,页面识别后找到可以确保唯一性的图片元素定位方法,所有的图片都在标签 ul > li 列表中,所以,我们可以获取图片 img 列表,然后遍历 img 列表,逐个下载即可。
定位 img 列表的 CSS Selector 语法是 ul#comicContain li img 。
![imag]()
失败了……
将以上的元素定位写入代码,修改后,先缩小话的 for 循化范围成从第 1 话开始到第 2 话结束,调试运行 py。
有点小确幸,多谢佛祖保佑,脚本运行通过,没有报错。
![imag]()
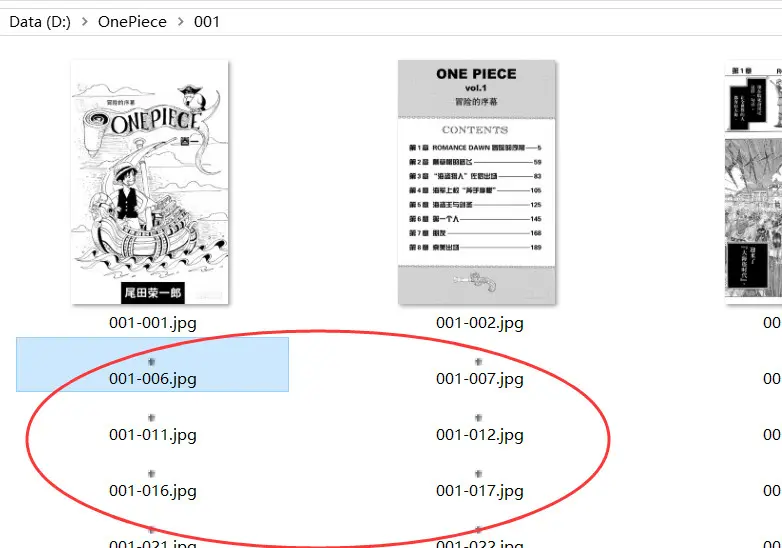
打开本地磁盘,查看保存的图片。
糟糕,除了前面几张图,后面全部都是一模一样的小图片,以我的多年工作经验来分析——哎呀妈,这些都是占位图啊!
![imag]()
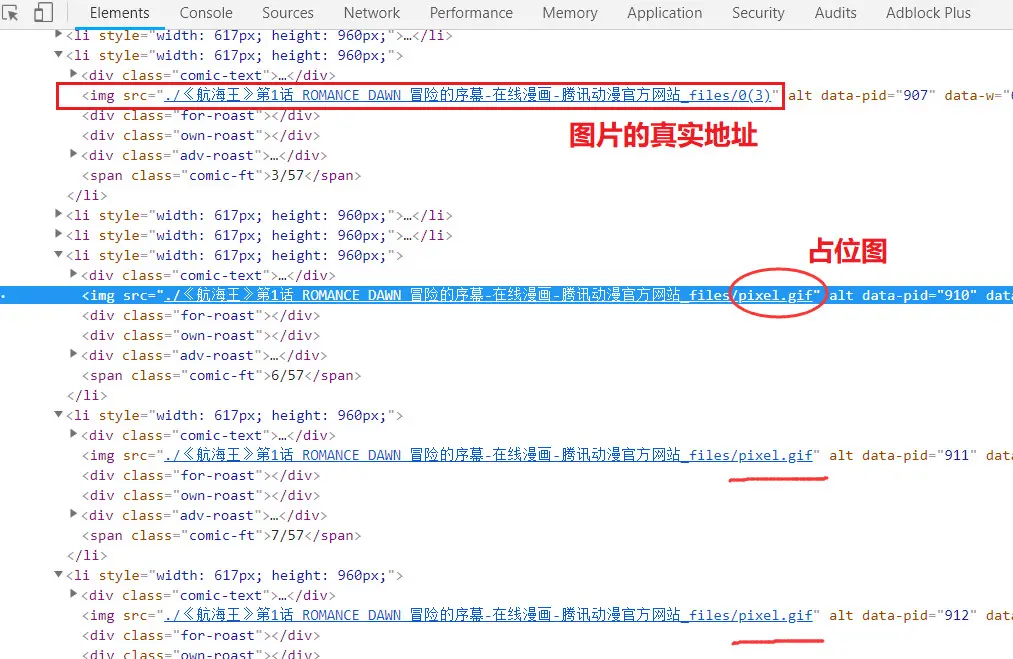
打开网页验证下自己的猜想。
![imag]()
确实像猜想的那样,当我没有浏览到处于页面下方的图片时,那里只有占位图,当页面向下滚动快要到达占位图时,img 标签的 src 会被替换成真实的资源 url,然后页面才加载图片。
如何处理懒加载页面?
那么,问题就显而易见了,这个页面使用了“懒加载(lazy load)”,也叫做“延迟加载”。不过,想想又觉得理所应当,像这样包含大量大图的页面,不延迟加载才是怪事。
惰性载入(英语:Lazy loading、Infinite Scroll,又称延迟载入、懒载入、无限卷动、瀑布流),是一种设计模式,被运用在软体设计和网页设计当中,对于网页界面,其特征为使用者透过滑鼠,卷动浏览页面,直到页面下方时,就会自动载入更多内容;有多数网站采用这项网页设计,例如 Google 图片搜索、Google+、Facebook、Twitter、Pinterest 和维基百科的 Flow 讨论系统。也有结合无限卷动和多页,两著特性的网页设计。
– Wikipedia
使用关键字“python 页面抓取 懒加载”在 Google 搜索一番,又使用相似的英文搜索,结果都指向一种解决方式:通过 Selenium 滚动页面触发 js 加载图片。
既然要用 Selenium,那么,我还是换回 Java 来实现这次的需求吧,谁让咱是 Java + Selenium 老手呢(见历史文章),转而去整 Python + Selenium 的话,又要重新学习,我可不想重复造轮子。
Java 实现爬虫,第 2 版
很久前,我就已经在 github 上开源了一个 UITest 框架,借助 Selenium 和 Appium,地址是 WebAndAppUITesting 。这么小的需求没必要使用这套框架,从工程里借鉴一些代码即可。
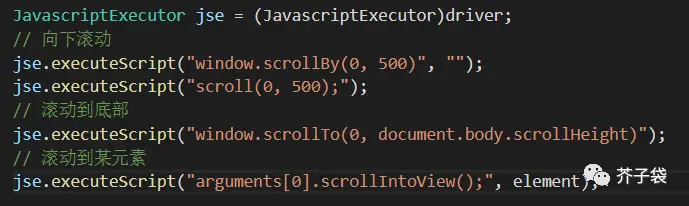
第 1 版上我需要增加页面滚动的逻辑,按之前的经验需要加入 JavaScript 执行器的代码,可用的方式大致有以下几种:
![imag]()
不多说了,直接上代码吧
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
| package com.uitest;
import java.io.File;
import java.io.InputStream;
import java.net.URL;
import java.nio.charset.Charset;
import java.nio.file.FileAlreadyExistsException;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;
import java.nio.file.StandardOpenOption;
import java.util.Arrays;
import java.util.List;
import java.util.concurrent.TimeUnit;
import org.openqa.selenium.By;
import org.openqa.selenium.JavascriptExecutor;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.chrome.ChromeDriver;
import org.openqa.selenium.chrome.ChromeOptions;
public class DownloadOnePiece {
public static void main(String[] args) throws Exception {
download();
}
public static void download() throws Exception {
int firstChap = 001;
int newestChap = 947;
String baseUrl = "https://I.cannot.tell.the.real.url/post/10%03d/";
String baseDir = "D:\\OnePiece\\%03d\\";
String baseFile = "D:\\OnePiece\\%03d\\%03d-%03d.jpg";
String chapterName = "";
System.setProperty("webdriver.chrome.driver", "C:\\chromedriver.exe");
ChromeOptions options = new ChromeOptions();
options.addArguments("headless");
WebDriver driver = new ChromeDriver(options);
driver.get("https://I.cannot.tell.you.the.real.url");
driver.manage().window().maximize();
driver.manage().timeouts().implicitlyWait(5, TimeUnit.SECONDS);
JavascriptExecutor js = (JavascriptExecutor) driver;
List<WebElement> imgList = null;
for (int idxChap = firstChap; idxChap <= newestChap; idxChap++) {
driver.get(String.format(baseUrl, idxChap));
Thread.sleep(2 * 1000);
chapterName = driver.findElement(By.cssSelector("span.title-comicHeading")).getText();
toLog(String.format("# [%03d] %s", idxChap, chapterName));
createFolder(String.format(baseDir, idxChap));
imgList = driver.findElements(By.cssSelector("ul#comicContain li img"));
int imgIndex = 1;
for (WebElement img : imgList) {
if (img.getAttribute("id").contains("adBottom")
|| img.getAttribute("id").contains("adTop")
|| img.getAttribute("src").contains("006xpM3Tgy1feta1hkppuj30m8076wgh.jpg")) {
continue;
}
js.executeScript("arguments[0].scrollIntoView();", img);
Thread.sleep(300);
String srcUrl = img.getAttribute("src");
if (srcUrl.contains("pixel.gif")) {
toLog(String.format("fail to load img [%03d - %03d]", idxChap, imgIndex++));
continue;
}
String destFile = String.format(baseFile, idxChap, idxChap, imgIndex);
toLog(String.format("下载[%03d]:%s", imgIndex, srcUrl));
imgIndex++;
downloadFile(srcUrl, destFile);
}
}
driver.quit();
}
private static boolean downloadFile(String url, String destFile) throws Exception {
try {
InputStream in = new URL(url).openStream();
Files.copy(in, Paths.get(destFile));
} catch (FileAlreadyExistsException e) {
toLog("文件已存在:" + destFile);
return false;
} catch (Exception e) {
e.printStackTrace();
return false;
}
return true;
}
private static void createFolder(String folderName) {
File dirFile = new File(folderName);
boolean bFile = dirFile.exists();
if (bFile == false) {
bFile = dirFile.mkdirs();
}
if (bFile == true) {
toLog("Create folder successfully! -- " + folderName);
} else {
toLog("Create folder error! -- " + folderName);
}
}
public static void toLog(String newline) {
try {
List<String> lines = Arrays.asList(newline);
Path file = Paths.get("D:\\onepiece.log");
System.out.println(newline);
Files.write(file, lines, Charset.forName("UTF-8"), StandardOpenOption.CREATE, StandardOpenOption.APPEND);
} catch (Exception e) {
e.printStackTrace();
}
}
}
|
需要注意的是,为了效率考虑,实际运行抓取图片时,我使用了“无界面的浏览器”,即代码段 options.addArguments("headless"); 。
调试的时候可以注释该行,在有界面的情况下,观察运行效果。
另外提一句,我当前使用的 chrome 和 driver 在 headless 模式下出现了 bug,变量 chapterName 总是空字符串,而有界面时,没有这个问题。
再次运行代码
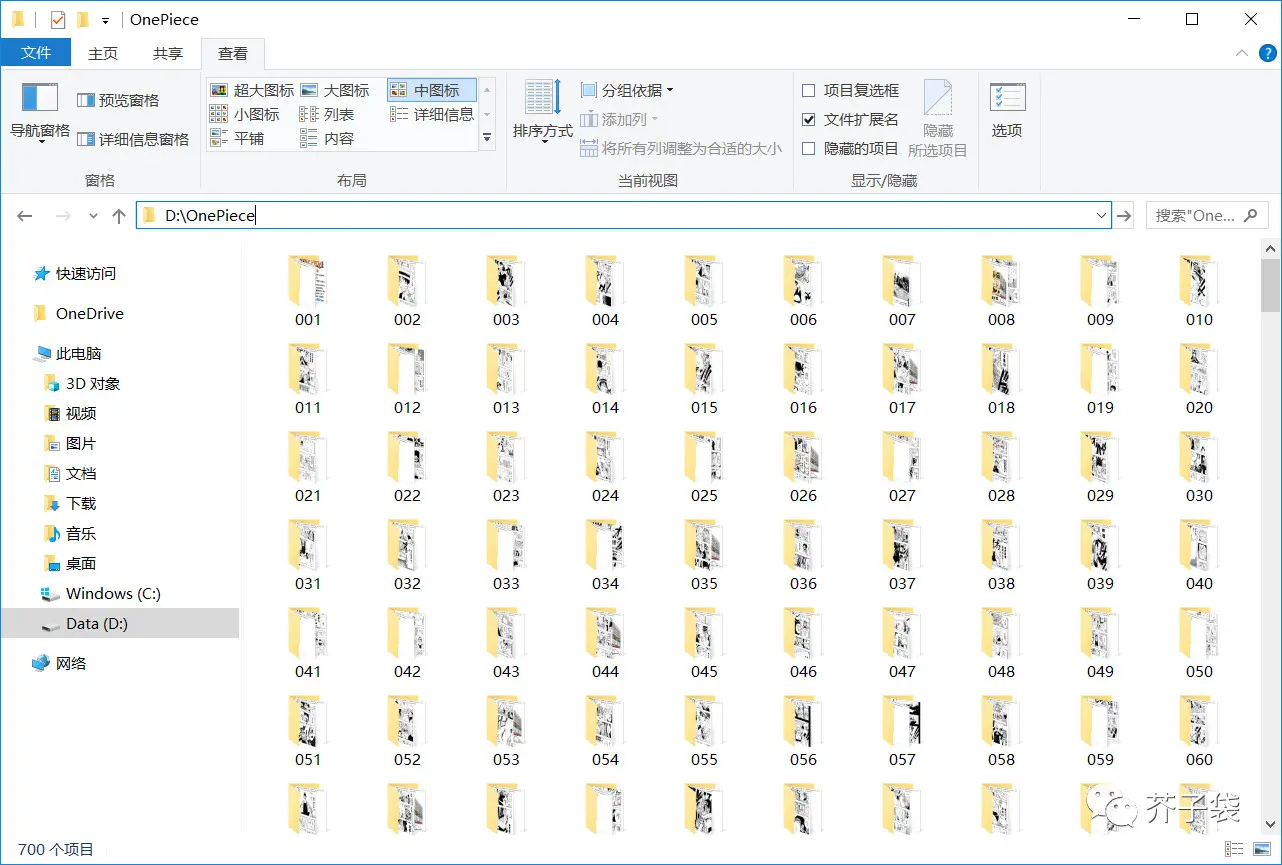
再次运行代码,这次世界清静了,程序正常运行没报错,图片也正常下载了。只是代码执行比较慢,因为,为了保障页面加载、图片抓取的成功率,加了一些 sleep 等待。好在使用 headless 模式运行,把它收起在后台默默执行,也不影响我做别的事情。
一段时间后……
![imag]()
看漫画喽